
Development of an algorithm to classify primary care electronic health records of alcohol consumption: experience using data linkage from UK Biobank and primary care electronic health data sources
This project developed a novel algorithm to categorise alcohol consumption using primary care electronic health records (EHRs) before assessing its reliability by comparing this classification with self-reported alcohol consumption data obtained from the UK Biobank (UKB) cohort.
Data were obtained on almost 19,000 people in the UKB aged 40-69 years who lived in Scotland and had linked primary care data.
First, the team compiled a comprehensive list of all Read V.2 alcohol-related codes by exploring all the categories and subcategories of the thesaurus with an explicit mention of alcohol or alcohol-related terms. Second, the primary care database was queried to select all participants who had a Read Code indicating alcohol intake. Qualitative descriptors of alcohol consumption (e.g. light/moderate/heavy drinker) or a quantitative record containing the number of units of alcohol consumed per week were extracted. Two clinicians independently assessed the different descriptors and assigned these to one of the previously described five categories. Disagreement was minor and resolved by discussion with a third clinician to make the final decision. Agreement between the two sources (UKB and novel algorithm) was assessed using Cohen’s kappa and the McNemar-Bowker test.
The algorithm allowed the reduction of 86 Read Codes containing 102 different descriptors from Primary Care into a meaningful classification of five categories of alcohol consumption.

The overall agreement between the UKB data and the algorithm using primary care Read Codes was 59.6% and this proportion only varied by −2.1%+1.7% regardless of the algorithm rules and periods in between assessments and age. Interestingly, although the kappa statistic was not substantially different, female participants showed a much higher agreement than their male counterparts (up to +13.5%). Kappa analysis also showed slightly better agreement for the algorithm of Read Codes only containing numerical values of units of alcohol. This finding suggests that when a more objective measurement is used classification improves. The great variety of Read Codes related to alcohol consumption containing a qualitative description of the drinking patterns introduces obvious subjectivity in the assessment process as the professional will have to make a judgement and decide which category the individual falls in.
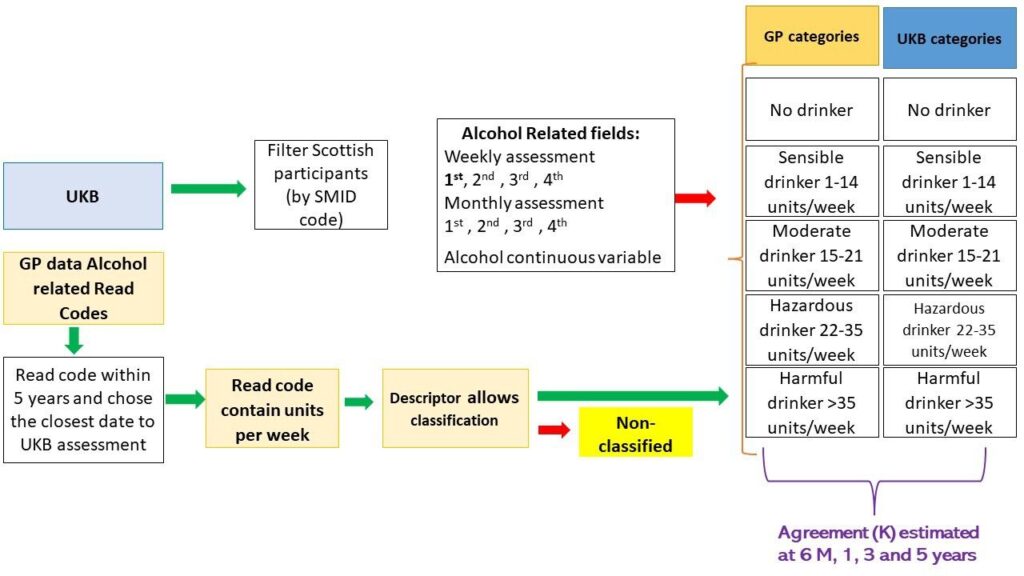
The algorithm permitted meaningful classification into five categories, which could considerably reduce the number of descriptors utilised in the primary care records. Results also showed that there may be potentially a systematic misclassification of patients in GP records, which merits more in-depth study.
Improving and standardising the recording system of alcohol consumption should be a priority that would be relatively easy to implement. The analysis of this data in clinical records serves as a good example of how progress in Health Data Science can contribute to improvement in individual and societal health.
Output
Fraile Navarro, D., Azcoaga-Lorenzo, A., Agrawal, U., Jani, B., Fagbamigbe, A., Currie, D. B., Baldacchino, A M. & Sullivan, F. Development of an algorithm to classify primary care electronic health records of alcohol consumption: experience using data linkage from UK Biobank and primary care electronic health data sources BMJ Open 2022;12:e054376. doi: 10.1136/bmjopen-2021-054376